






引言
随着互联网技术的飞速发展,企业对日志数据的依赖程度越来越高。日志数据不仅记录了系统的运行状态,还包含了用户行为、系统性能等信息,对于故障排查、性能优化、安全监控等方面具有重要意义。然而,传统的日志分析方法往往效率低下,难以满足实时性要求。为了解决这一问题,本文将介绍一种基于Flume的日志实时分析平台,旨在提高日志处理和分析的效率。
Flume简介
Flume是一个分布式、可靠、高效的日志收集系统,它能够从多个数据源收集数据,并将数据传输到指定的目的地。Flume主要由Agent、Source、Channel和Sink四个组件构成。Agent是Flume的基本工作单元,负责数据的收集、传输和处理。Source负责从数据源读取数据,Channel负责暂存数据,Sink负责将数据传输到目的地。
Flume日志实时分析平台架构
Flume日志实时分析平台采用分布式架构,主要包括以下几个模块:
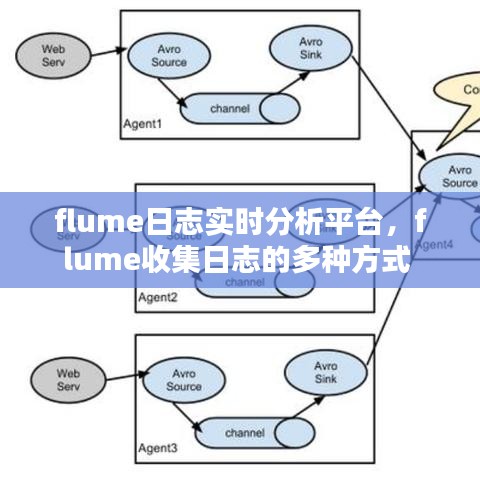
- 数据采集模块:通过Flume Agent从各个数据源(如Web服务器、数据库、应用程序等)收集日志数据。
- 数据预处理模块:对采集到的原始日志数据进行清洗、过滤和格式化,以便后续分析。
- 数据存储模块:将预处理后的数据存储到分布式存储系统(如Hadoop HDFS、Elasticsearch等)中,以便进行大规模数据分析和查询。
- 数据分析模块:利用大数据分析技术(如Spark、Flink等)对存储在分布式存储系统中的数据进行实时分析,生成可视化报表和预警信息。
- 数据展示模块:通过Web界面展示分析结果,方便用户查看和监控。
数据采集与预处理
数据采集是Flume日志实时分析平台的基础。通过配置Flume Agent,可以轻松地从各种数据源采集日志数据。例如,可以从Web服务器采集Apache日志、从数据库采集SQL日志、从应用程序采集运行日志等。采集到的原始日志数据可能包含噪声、重复信息和不规则格式,因此需要进行预处理。预处理模块主要包括以下功能:
- 日志清洗:去除日志中的无用信息,如空行、重复行等。
- 日志过滤:根据业务需求,过滤掉不相关的日志数据。
- 日志格式化:将不同格式的日志数据转换为统一的格式,方便后续分析。
数据存储与分析
预处理后的数据需要存储到分布式存储系统中,以便进行大规模数据分析和查询。Flume日志实时分析平台通常采用以下存储系统:
- Hadoop HDFS:作为大数据存储的基础设施,HDFS提供了高可靠性和高吞吐量的存储能力。
- Elasticsearch:基于Lucene搜索引擎,Elasticsearch提供了强大的全文检索和实时分析功能。
数据分析模块利用Spark、Flink等大数据分析技术对存储在分布式存储系统中的数据进行实时分析。分析结果可以包括:
- 系统性能指标:如CPU、内存、磁盘使用率等。
- 用户行为分析:如用户访问量、页面浏览量、点击率等。
- 异常检测:如系统错误、恶意攻击等。
数据展示与监控
为了方便用户查看和分析结果,Flume日志实时分析平台提供了Web界面。用户可以通过Web界面实时查看分析报表、监控系统状态、配置分析任务等。此外,平台还支持邮件、短信等预警机制,当检测到异常情况时,可以及时通知相关人员。
总结
Flume日志实时分析平台通过整合Flume、Hadoop、Elasticsearch等大数据技术,实现了日志数据的实时采集、预处理、存储、分析和展示。该平台具有以下特点:
- 分布式架构:提高了系统的可靠性和可扩展性。
- 实时性:支持实时数据采集和分析,满足业务需求。
- 高效性:利用大数据技术,提高了数据处理和分析的效率。
- 易用性:提供Web界面,方便用户操作和管理。
Flume日志实时分析平台为企业提供了强大的日志数据处理和分析能力,有助于企业更好地了解业务状况、优化系统性能、提高运维效率。
转载请注明来自马鞍山同杰良,本文标题:《flume日志实时分析平台,flume收集日志的多种方式 》






 皖ICP备2022015489号-1
皖ICP备2022015489号-1