






什么是YOLOv3
YOLOv3(You Only Look Once version 3)是一种流行的实时目标检测算法,由Joseph Redmon等人于2018年提出。YOLO(You Only Look Once)系列算法的核心思想是将目标检测任务视为一个回归问题,通过一个神经网络直接预测出图像中所有物体的边界框(bounding box)和类别概率。YOLOv3在YOLOv1和YOLOv2的基础上进行了改进,提高了检测速度和准确性。
YOLOv3的工作原理
YOLOv3的工作原理可以概括为以下几个步骤:
输入图像:首先,将输入图像进行预处理,包括调整图像大小、归一化等。
特征提取:使用深度卷积神经网络(CNN)提取图像的特征图。
预测边界框和类别概率:在特征图上,YOLOv3会预测每个网格单元(grid cell)中可能存在的物体的边界框和类别概率。
非极大值抑制(NMS):对预测的边界框进行非极大值抑制,以去除重叠的边界框,只保留最有可能的边界框。
输出结果:最终输出每个物体的边界框、类别和置信度。
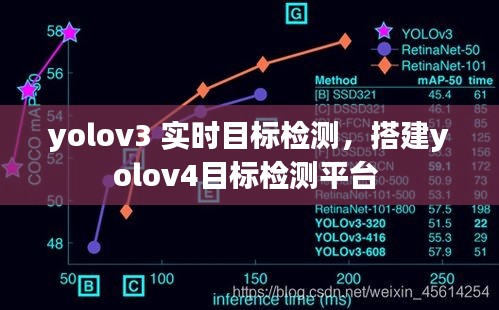
YOLOv3的改进之处
YOLOv3相较于前代算法,主要在以下几个方面进行了改进:
多尺度特征融合:YOLOv3使用了不同尺度的特征图进行融合,以提高检测的准确性和鲁棒性。
锚框(Anchor Boxes)改进:YOLOv3引入了更合理的锚框设计,使得模型能够更好地适应不同大小的物体。
路径网络(Path Network):YOLOv3引入了路径网络,允许模型在不同尺度的特征图之间进行信息传递,从而提高检测性能。
损失函数优化:YOLOv3对损失函数进行了优化,使得模型在训练过程中能够更好地平衡边界框的回归和类别预测。
YOLOv3的应用场景
YOLOv3由于其实时性和准确性,被广泛应用于各种场景,包括但不限于:
自动驾驶:在自动驾驶系统中,YOLOv3可以用于实时检测道路上的车辆、行人、交通标志等,为自动驾驶车辆提供决策支持。
视频监控:在视频监控领域,YOLOv3可以用于实时检测和识别视频中的异常行为,如入侵、打架等。
工业自动化:在工业自动化领域,YOLOv3可以用于检测生产线上的缺陷或异常,提高生产效率。
医疗影像分析:在医疗影像分析中,YOLOv3可以用于检测图像中的病变区域,辅助医生进行诊断。
YOLOv3的局限性
尽管YOLOv3在实时目标检测领域取得了显著的成果,但它也存在一些局限性:
对小物体的检测能力有限:由于锚框的设计,YOLOv3对小物体的检测能力相对较弱。
对复杂背景的鲁棒性不足:在复杂背景下,YOLOv3可能会受到干扰,导致检测精度下降。
计算资源消耗较大:YOLOv3的网络结构较为复杂,对计算资源的要求较高。
总结
YOLOv3作为一种高效的实时目标检测算法,在多个领域都得到了广泛应用。它通过将目标检测任务视为回归问题,实现了快速、准确的检测。然而,YOLOv3也存在一些局限性,需要进一步的研究和改进。随着深度学习技术的不断发展,相信未来会有更多高效、鲁棒的目标检测算法出现。
转载请注明来自马鞍山同杰良,本文标题:《yolov3 实时目标检测,搭建yolov4目标检测平台 》



 皖ICP备2022015489号-1
皖ICP备2022015489号-1